Lecture 12 Query Execution Part 1
Today‘s agenda
- Processing Models
- Access Methods
- Modification Queries
- Expression Evaluation
Processing Models
Processing Models(处理模型) 定义了数据库系统如何实现不同查询的执行
理解processing model的最佳方式 是 从零开始编写数据库引擎的代码
之前的lecture中我们涉及到 查询语句 后面 的 代数运算符的树状结构,如何编写代码以实现操作符的所有功能? 需要为每个操作符编写的代码以特定算法的代码 -- 比如哈希连接 排序归并操作等 需要实时组装整个流程
逐一介绍三种不同的操作符模型
Iterator Model
迭代器模型 -- 最简单 通过一个实例来了解
包含三个函数
设想为每个操作符定义一个规范的函数定义,无论是扫描读取文件,索引选择,连接,聚合,还是投影,所有的操作符树节点熟悉的操作中,我们都希望他们具有相同的签名
里面的代码是取决于这个操作符的功能的 但签名的一致性,才能够混合搭配使用
签名长什么样?
签名的三个关键组成部分:
open() close() 有点像构造函数和析构函数
next() 核心部分
next有点像cpp和Java中的迭代器中的next方法 -- 就是往后循环 但是扫描的是正在生成的记录 -- 像是在询问 谁需要我(这个操作符)生成的数据 -- 下一个function是引入数据
→在每次调用时,运算符将返回单个元组或 eof 标记(如果没有更多元组)。
→运算符实现一个循环,该循环对其子项调用 Next() 以检索其元组,然后处理它们。
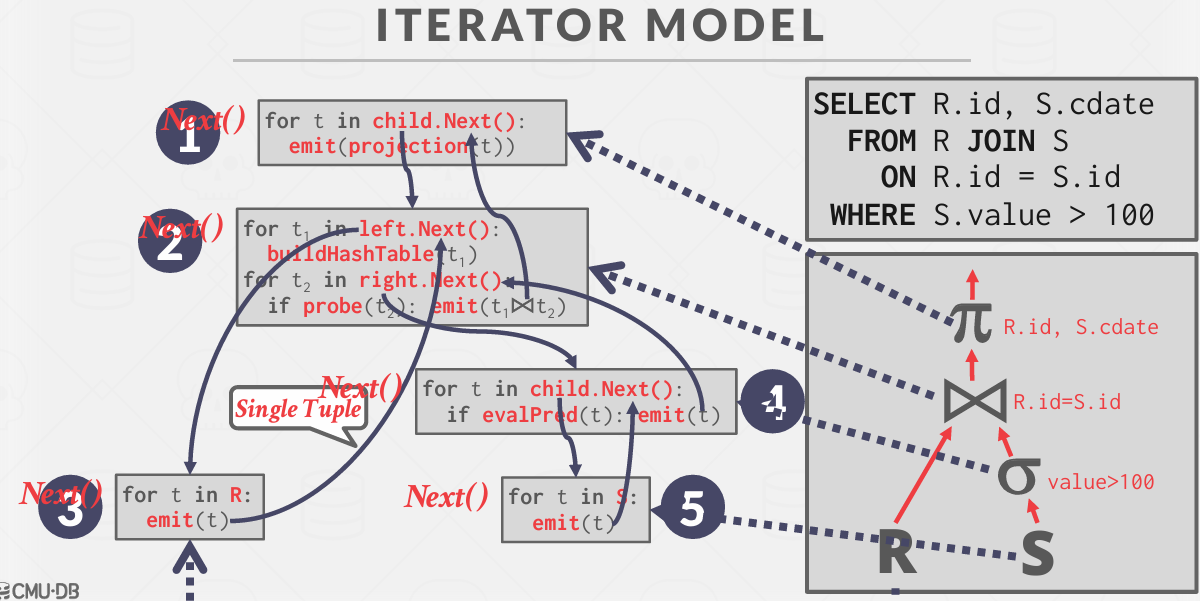
从最简单的开始看
右下角的意思是 对于关系S中的每个记录t,打开并简单的输出t
然后是 读取到一个child.Next() -- 读取了上一个的输出作为输入 然后进行了一个选择输出
操作是从顶部开始打开的 在运行的时候 是倒着运行上去的
在这里 是 一条记录1 2 3 这个环就循环一次 直到 读取完
一旦2 4 5 第一条记录循环回去了 就直接在hash table比较 然后进入1
在切换函数的时候 有多少条记录就有多少个循环 大量的函数调用 大量的函数调用会有很多开销
第二个是 如果有很多函数被调用 函数代码是没有机会保持在指令缓存中 会被交换出去 所以切换函数并不好

事实上 有一系列数据库 还是保留了这种model
随着近代内云南的增大 -- 出现了一些新的model
Materialization Models
物化模型
当一个运算符被调用时 设想下一个操作 我们接下来做的是整个输出 -- 然后将结果返回给调用者
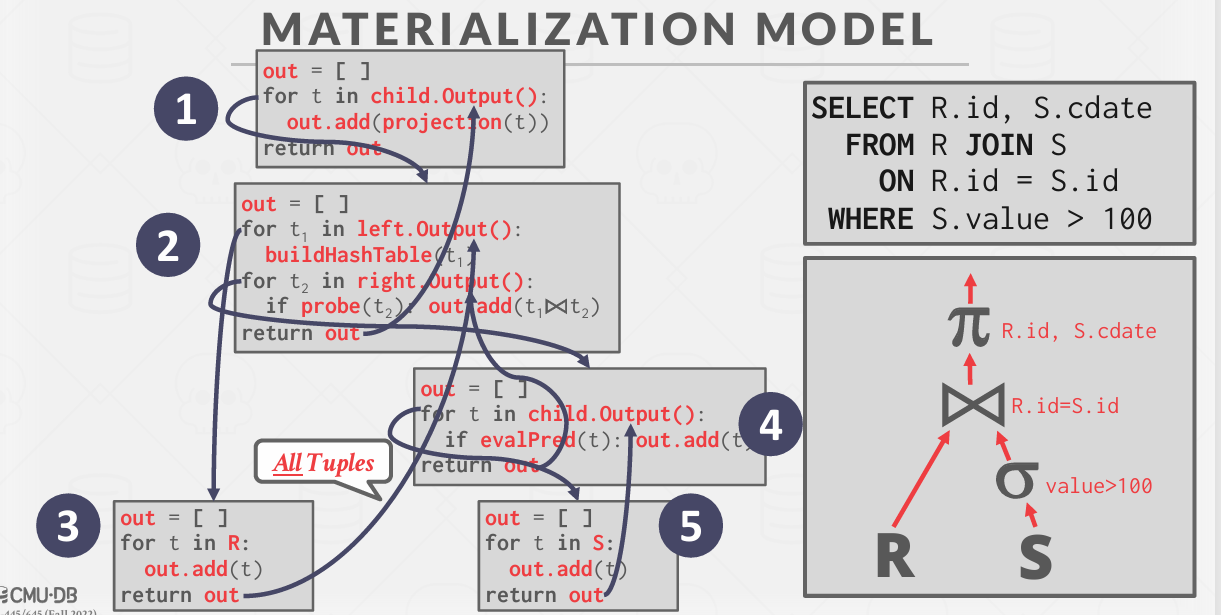
2 3 的循环制运行一次
这种情况再什么情况下使用?
当你的查询不涉及需要跨网络传输的大表时,(这种情况喜爱OLTP中常见,这些环境下的工作负载主要是事务性的,比如更新一条记录这种一个小操作的操作) is good
更适合 OLTP 工作负载,因为查询一次只访问少量元组。
→降低执行/协调开销。
→更少的函数调用
不适用于具有大型中间结果的 OLAP 查询。
Vectorization Model
在90年代末 出现了缓存
CPU和内存中间加了缓存 需要开始关注缓存 -- 切换成本也变得更高
在数据库系统算法与实现的早期案例中 转向向量化模型的关键在于 我们基本上认识到有两点式我们希望着重强调的
我们希望在每次操作符调用之间获取所有记录与仅获取一个元组之间找到一个折中方案 以得到稍小的数据集
如果我能获取一批记录 不是整个结果集 但也不止一个 也能进行向量化处理
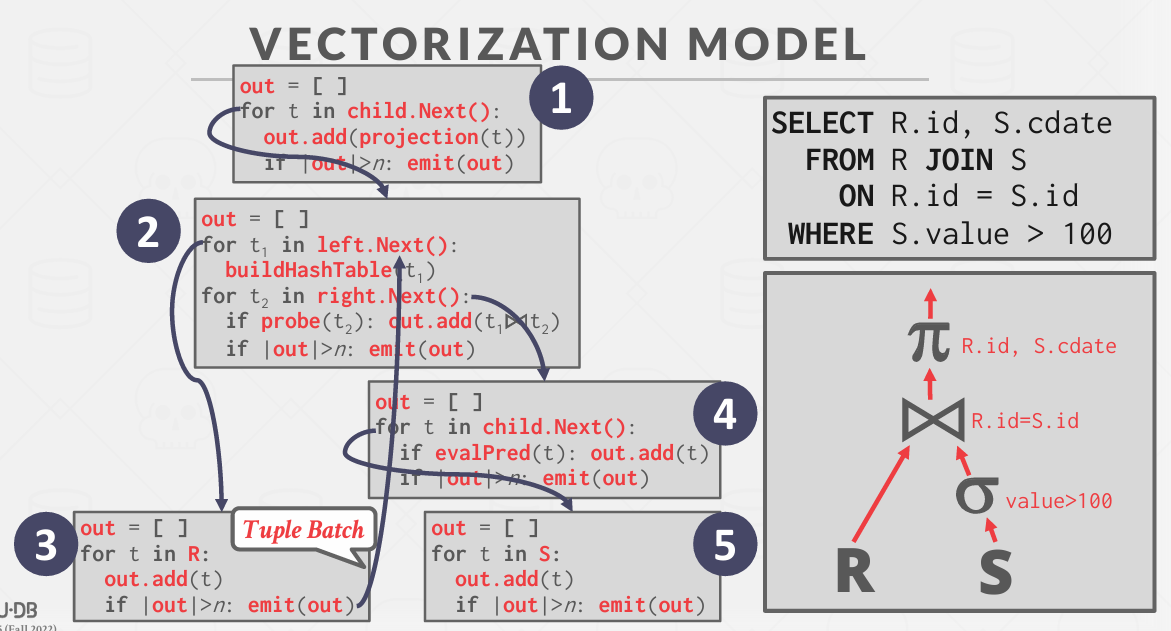
可以进行单一数据多数据操作
在物化模型中 如果其中一个输出4包含十亿行 就需要在内存中分配十亿行 这会占用大量的空间
Plan Processing Direction
- Top-to-Bottom
Bottom-to-Top
调用设置树 可以自顶向下的方式设置 或者是 自底向上的方式设置
自底向上方法的一个优势在于 在搭建系统的过程中 可能存在一些优化 可以运用一些特殊的优化技巧
access methods
在每个树中 操作符的根节点是访问实际数据的地方
在该树的底部 我们需要决定如何访问底层文件中的记录 -- access methods 访问方法
Three basic approaches:
- Sequential Scan 顺序扫描 主流
- Index Scan 索引 高效
- multi-index scan
Sequential Scan
遍历每一页内容

DBMS维护了一个游标 -- 跟踪访问的最后一个page -- 方便转到下一页

Data Skipping
Approach 1: Approximate Queries(Lossy)
高级数据库课程会讲
Approach 2: Zone Maps(Lossless)

页面中属性值的预计算聚合。DBMS 首先检查区域映射以决定是否要访问该页面。
比如说我可能会有好多选择查询 比如说我要找100和300之间的 我要找大于400的等等
很多时候 文件都被横向分成了好多zone区域
我们可以针对每个区域创建某些聚合的信息 -- zone map
先访问zone map决定放不访问数据
但要确保 更新数据的时候 zone map被更新
Index Scan
使用哪个索引取决于:
→索引包含哪些属性
→查询引用哪些属性
→属性的值域
→谓词组合
→索引是否具有唯一键或非唯一键
这些将在lecture14讲

我们需要去选择使用哪个索引 -- 这也意味着我们要跟踪一些数据 (以后会讲的)
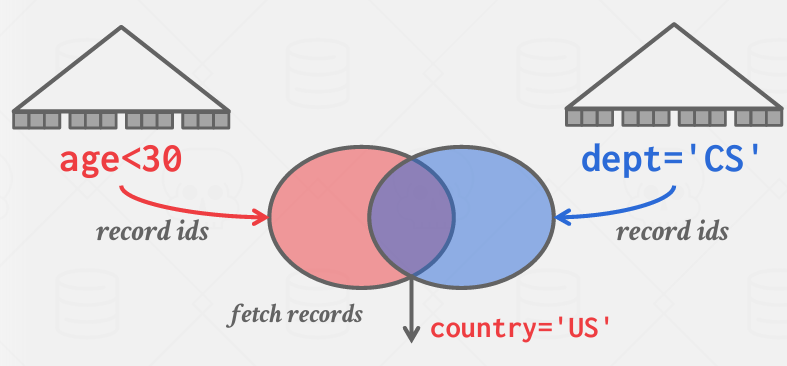
Multi-Index Scan
还没有接触到page中的数据
多个索引扫描后 合并命中结果 然后再去访问数据
UPDATE/DELETE 操作
- Child Operators Pass Record IDs for Target Tuples:
- 在执行更新或删除操作时,通常需要指定要修改或移除的具体记录。在数据库系统中,这些记录通过唯一的标识符(Record ID)来识别。
- 子操作符(如扫描操作符、索引查找操作符等)负责找到目标元组,并将它们的Record IDs传递给执行更新或删除操作的操作符。
- Must Keep Track of Previously Seen Tuples:
- 当执行这些操作时,尤其是当涉及到多个步骤或者复杂查询时,系统可能需要记住已经处理过的元组以避免重复处理或遗漏。
这可以通过维护一个已处理元组的列表或使用其他机制(例如哈希表)来实现,确保每个元组仅被正确地更新或删除一次。
INSERT 操作
对于插入新数据到数据库中有两种主要方法:
- Materialize Tuples Inside of the Operator (选择1):
- 在这种方法中,操作符会在其内部创建或“物化”新的元组。这意味着所有关于新记录的信息都会首先在操作符内部组装完成。
- 一旦元组被完全构建,它就可以被添加到数据库中。这种方法可以提供对插入过程的更多控制,比如可以在插入前进行额外的验证或转换。
- Operator Inserts Any Tuple Passed in from Child Operators (选择2):
- 另一种方法是直接插入从子操作符传来的任何元组。在这种情况下,操作符充当一个通道,它接收来自上游的数据并将其直接插入到数据库中。
- 这种方式简化了流程,减少了内存占用,因为不需要在操作符内部存储副本。但是,这也意味着任何必要的数据转换或验证必须在数据到达此操作符之前完成。
这是为了避免一个问题
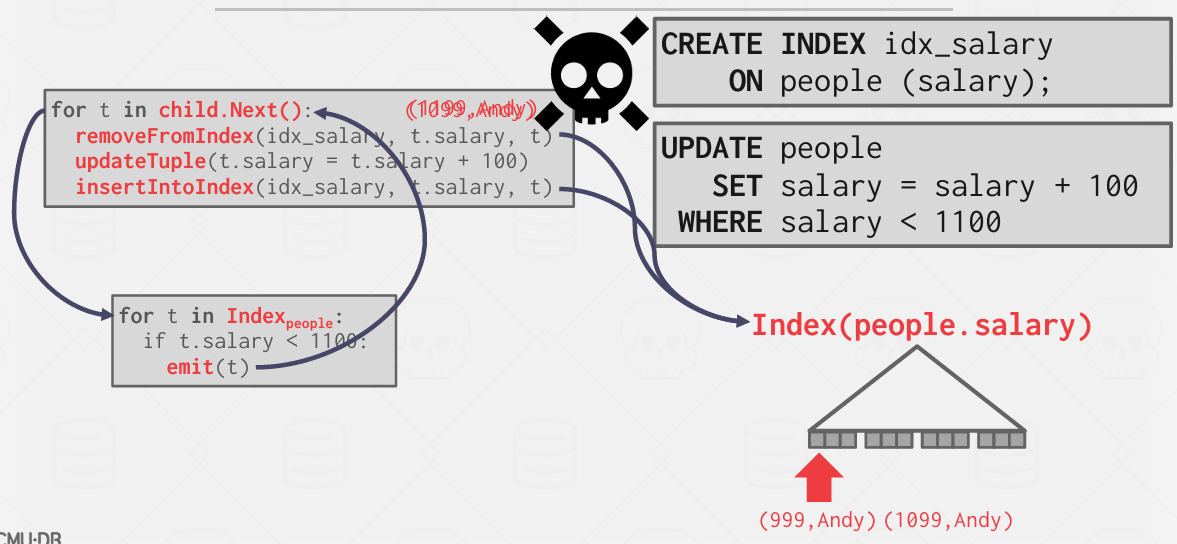
重复操作
解决方案:跟踪每个查询的修改记录 ID
expression evaluation
表达式求值

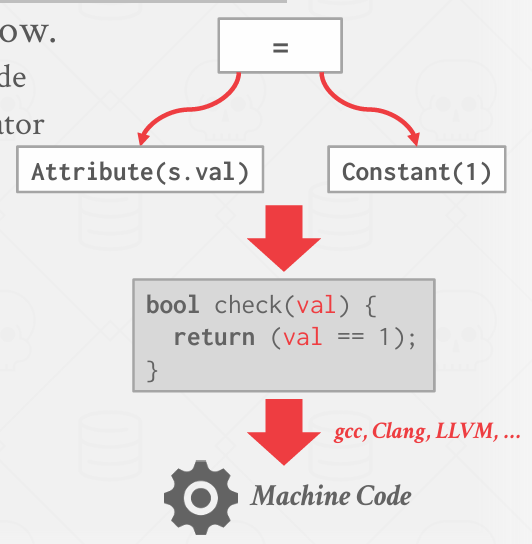
这张图解释了数据库管理系统(DBMS)如何将SQL查询中的WHERE子句表示为表达式树(expression tree)
缺点: 每次访问一个节点都要确定该结点的操作符应该执行什么操作
更好的方法: 一种更好的方法是直接评估表达式,而不是通过遍历表达式树。
这可以通过编译技术来实现,例如即时编译(JIT compilation)
使用编译器(如gcc、Clang、LLVM等)将表达式编译成机器码,从而提高执行效率。
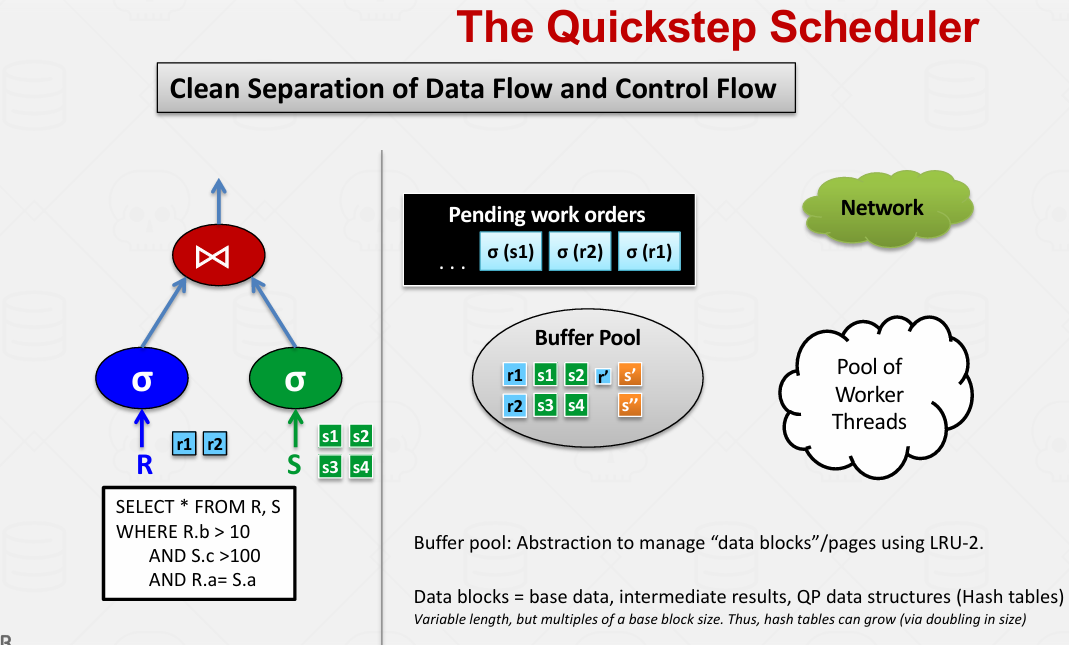
Scheduler
到目前为止,我们主要从数据流的角度来看待查询处理模型。控制流在处理模型中是隐含的。我们可以使用调度器使控制流更加明确。
如果使用Scheduler 会生成一个被称为“调度组件”的实体 在快速处理中我们称之为工作订单
数据就会被引入缓冲池 缓冲出在正常条件下运行 不再是从小至上调用操作符树了
实际上还是在遍历这棵树 并将调度任务放入调度器队列
然后就可以决定谁处理什么任务了(如果多个机器?)
然后处理完了就是r' 放入buffer pool
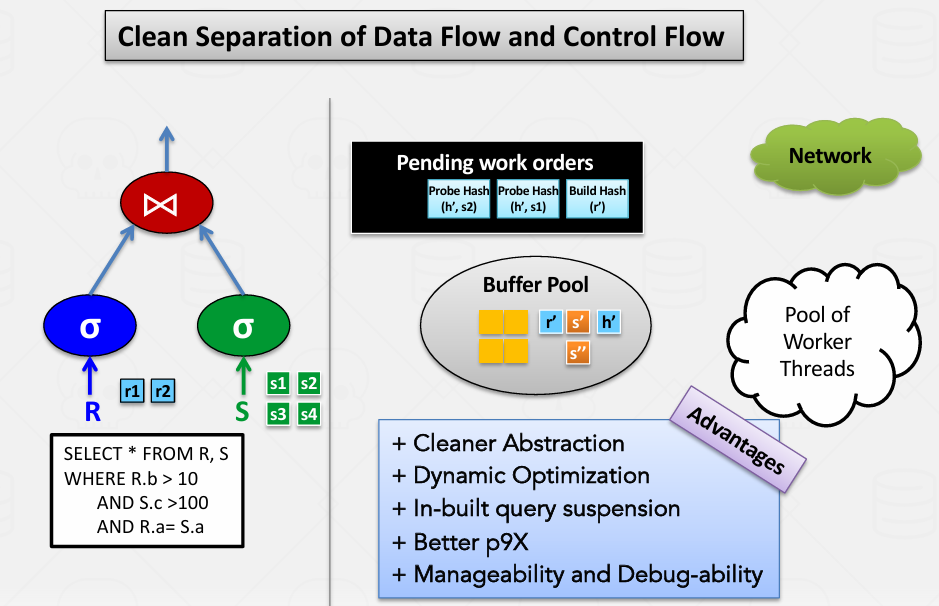
可以做一些有趣的事情
比如说系统中有四个查询正在进行 查询1已经完成一半 但新进的高优先级查询四需要立即处理 只需将查询四的所有任务放到队列前端
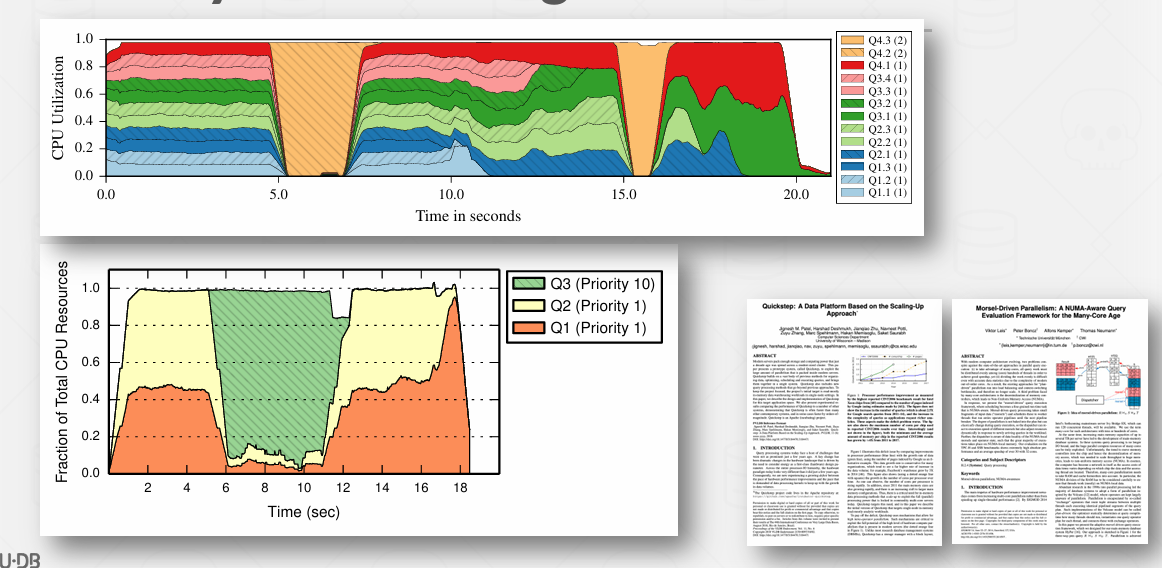
绿色查询进入后会接管所有资源